Programming Room.
Google Cloud Tips.
GAE Tips.
Google App Engine(GAE)に関するTipsです。
おしながき
- SDK1.9.32以降をEclipseで使う.
- ログ.
- index.htmlをサブディレクトリに置く.
- 管理者用ページの作成.
- リソースファイルの読み込み.
- 東京リージョンの使い方.
- /robots.txtでのエラー回避.
- Memcache利用上の注意.
- サービスの利用.
- タスクキュー(pushキュー)の利用.
- Cloud Tasksの使い方.
- Cloud Schedulerの使い方.
SDK1.9.32以降をEclipseで使う.2016/10/27
動機.
GAE/JのSDKはバージョン1.9.32から開発環境がEclipseからMavenに移ったようです。Eclipseに慣れているとMavenとか使いにくいので、Eclipseで最新の環境を使い続けられないかなー
ということです。
調べたところ、幸いもSDKの構成はほとんど変化がなくて、Eclipseプラグインも提供され続けているようです。
SDKのインストール.
まずは1.9.32以前と同様にここからSDKをダウンロードします。Googleのサイトをトップから順にたどるなら、
- GCPトップページの「コンピュート」 - 「App Engine」
- App Engineのページ下部の「その他のリソース」 - 「App Engine SDK」
- 「Download and Install the SDK for App Engine」ページの「Java」ボタン
- 「Download the App Engine SDK for Java」ページの「download」ボタン
で、SDKアーカイブをダウンロード開始です。
SDKアーカイブは適当なディレクトリに解凍します。「マイ ドキュメント」とか深い階層のディレクトリに置くと、パス名の長さや階層の深さ、あるいは日本語パスの問題で後々トラブルに悩まされることがあるので、c:\直下に適当なディレクトリ作るほうが確実です。
Eclipseプラグインのインストール.
Eclipseプラグインはここから最新をダウンロードできます。GCPトップページからはたどり方がわかりませんでした。GCPとは別扱いのようなサイトがあり、下記でたどれます。
- 「Google Developers」の「すべてのサービス」
- 「サービス」ページの「E」に分類されている「Google Plugin for Eclipse」
- 「Google Plugin for Eclipse」ページから、「What would you like to do?」-「Install」の「INSTALL PLUGIN」のリンク
- 「Google Plugin for Eclipse - Quick Start」ページから、使っているEclipseバージョンに応じたリンク
- 「Google Plugin for Eclipse 4.4 (Luna) Installation Instructions(Lunaの場合)」ページの説明に従い、Eclipseでインストール
企業など多人数で開発する場合は直接各個人PCのEclipseからダウンロードを行うより、代表者がアーカイブをダウンロードしておき、各個人はそのアーカイブからインストールするほうが効率がいいでしょう。ネットワーク負荷の軽減や、各自のバージョンをそろえられる利点があります。その場合は上記3の以降を下記の手順で行います。
- 「Google Plugin for Eclipse - Quick Start」ページから、「downloading and installing an archive of the update site」のリンク
- 「Installing the Google Plugin for Eclipse from a local update archive」ページから、使っているEclipseバージョンに応じた項目に従い、「the latest update site archive for Eclipse 4.4(Lunaの場合)」のリンクをクリック
プラグインのアーカイブをダウンロード後は、手順4のページの説明どおりにEclipseでインストールします。
ログ.2016/10/27
ログの出力.
通常のJavaと同様に、GAEでもjava.util.logging.Loggerクラスを使用してログを出力させることができます。
またUNIXのシステムログやAndroidのログと同様に、重要度・深刻度に応じてログのレベルを使い分けることができます。
ログの表示.
ログの表示方法は、動作環境によって違います。
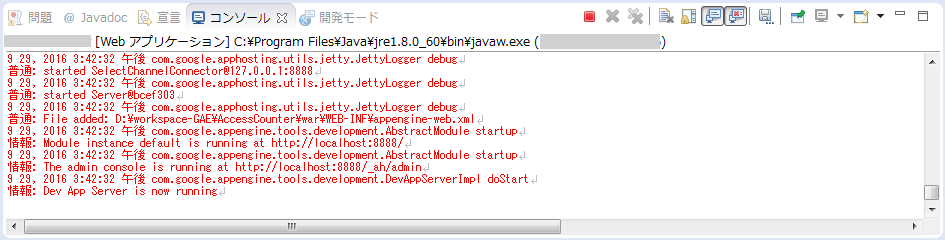
シミュレータのログ表示.
シミュレータでローカルデバッグ中は、Ecripseを使っているのなら「コンソール」タブに表示されます。↓こんな感じ。
デプロイしたアプリのログ表示.
デプロイ後の実動作環境ではGCPのコンソールにアクセスして表示します。ブラウザで下記URIにアクセスし、プロジェクトを作成した時のGoogleアカウントでログインしてください。ログイン済みならすぐにコンソールが表示されます。コンソール左上の「ツールとサービス」メニューから「ログ」を選ぶだけです。
https://console.cloud.google.com/
最低出力レベル.
実際に使ってみると、SDKのデフォルト設定ではレベルINFO以上のログしか出力されません。これはロガーに保存するログの最低レベルの設定があるためです。その設定ファイルが下記のファイルです。
(プロジェクトトップディレクトリ)/war/WEB-INF/logging.properties
このファイルのコメントに記されているように、このファイルの配置場所は appengine-web.xml に記載するようですね。デフォルトで
appengine-web.xml に書かれている場所が上記のディレクトリになっているだけです。変えることも可能でしょうが、変える必要に迫られたことがないので、変えたことはありません。
またこの設定は「ロガーに貯めるログの最低レベル」なので、貯まっていないログはGCPのコンソールで表示のレベルを変えても出力されません。
中を覗いてみるとデフォルトではたったのこれだけ。
# Set the default logging level for all loggers to WARNING .level = INFO
この「INFO」の部分を書き換えることで、より低いレベルのログも出力できるようになります。
しかしINFOより低いレベルを設定してみると、フレームワーク自身が出力しているログも増えるので、目的のログを探すのがちょっと面倒になったり、ログバッファがあふれるまでが早くなるかもしれません。
index.htmlをサブディレクトリに置く.2016/10/27
用途.
HTMLとかは まとめてサブディレクトリに置きたいけど、アクセスはサブディレクトリを意識せず「http://アプリID.appspot.com」で行いたい場合とか。
設定.
公式ドキュメント「The Welcome File List」にかかていますが、あまり詳しく述べられていません。分かったようなわからないような、説明不足です。
設定は (プロジェクトトップディレクトリ)/war/WEB-INF 下にある web.xml に記述します。「http://アプリID.appspot.com」で、
(プロジェクトトップディレクトリ)/war/html/index.html をアクセスする例です。
<welcome-file-list>
<welcome-file>html/index.html</welcome-file>
</welcome-file-list>
URIのパス部分は、 (プロジェクトトップディレクトリ)/war からの相対なので、上記のようになります。welcome-file要素のコンテンツに書く相対URIを"/"から始めるとエラーになりますので注意。
管理者用ページの作成.2016/10/27
用途.
管理者のみアクセス可能なページを作る際の方法です。アクセスしてきたユーザが管理者か否かはGoogleアカウントで判断します。
設定.
公式ドキュメント「Security and Authentication」に書かれています内容そのままです。設定は (プロジェクトトップディレクトリ)/war/WEB-INF 下にある web.xml に記述します。
下記はその例です。公式ドキュメントほぼそのままですが、簡単すぎてイジリようがないので。
<!-- プロジェクトの管理者のみ -->
<security-constraint>
<web-resource-collection>
<web-resource-name>admin</web-resource-name>
<url-pattern>/admin/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>admin</role-name>
</auth-constraint>
</security-constraint>
<!-- Googleアカウントでログインしているユーザのみ -->
<security-constraint>
<web-resource-collection>
<web-resource-name>profile</web-resource-name>
<url-pattern>/profile/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>*</role-name>
</auth-constraint>
</security-constraint>
url-pattern要素で指定したページ(URI)ごとに、アクセス可能なアカウントを3段階で制限できます。web-resource-name要素は適当で構わないようです。
- 管理者のみ : 上記の前半の例。role-name要素のコンテンツに「admin」を記述します。ここでいう管理者は、GCPのコンソール左上の「ツールとサービス」メニューから「IAMと管理」を選択した際に表示されるアカウントです。
- Googleアカウントでログインしているユーザのみ : 上記の後半の例で、role-name要素のコンテンツには「*」だけ記述します。
- 制限なし : securigy-constraint要素で設定しなければ、制限はなくなります。
この3段階のアクセス制限でよければ、web.xmlの設定のみで可能です。
それ以上に細かい設定をしたければ、自分で実装するしかありません。com.google.appengine.api.usersパッケージが使えると思います。
注意事項.
#1 : ajax.
アクセス制限している場合、GAEへのアクセスがGAEによって、googleへのログインページへリダイレクトされたり、ユーザエージェント(たいていはブラウザ)のエンドユーザに対してGAEへのアクセス許可を求めるページへリダイレクトされることがあります。このアクセスがajaxだったりすると、リダイレクトできずに(してもエンドユーザは確認する手段がない)、ユーザエージェントでエラーになる可能性があります。
解決するには、アクセス制限しているURIへは、ajaxアクセスより先に、HTMLなどエンドユーザが操作可能なページリクエストをさせるように、サイトを構成する必要があります。スタティックなHTMLコンテンツはGAE外のWEBサーバに置き、ajaxアクセス先だけGAEを使おうとすると、この問題に突き当たります。ajaxアクセスをJavaScriptで書いてみて、上記のリダイレクトを捌けないか探ってみたのですが、JavaScriptではリダイレクトのコンテンツが返っててきたのか否かを判断できず、解決できませんでした。スタティックなHTMLコンテンツもGAE上に置いて、スタティックなHTMLコンテンツ自身とajaxアクセスのURIをsecurity-constraint要素で一緒に保護するしか解決方法がないような気がします。そもそもajaxアクセスに保護が必要なら、それを行うHTMLコンテンツ自身も保護が必要なページでしょうから、HTMLコンテンツの立場としてもこれでいいような気もします。
もしどなたか$.ajax()の返すjqXHRオブジェクトから、GAEがリダイレクトしようとしてるのか否かを判断するよい方法をご存知の方おられましたら、教えてください。
#2 : アクセス制限必要/不要URIの混在とwelcome-file-listの関連.
アクセス制限が行われるのはurl-pattern要素に記述したURIにマッチするものだけのようです。公式ドキュメント「The Welcome File List」に記載されているようにwelcome-file-list要素をweb.xmlに記述していると、「http://アプリID.appspot.com」または「http://アプリID.appspot.com/」のように省略したURIでアクセスできますが、この場合url-pattern要素にアクセス制限したいURIだけが記述してあっても、省略したURIにはマッチしないのでアクセス制限の対象になりません。
下記のように省略したケースも併記する必要があります。
<security-constraint>
<web-resource-collection>
<web-resource-name>admin</web-resource-name>
<url-pattern>/</url-pattern>
<url-pattern>/index.html</url-pattern>
</web-resource-collection>
...
しかし実際に上記の「/」のみのパターンも併記して試してみると、「http://アプリID.appspot.com/xxxx」のようなURIまでもアクセス制限されてしまいました。「/」のみパターンは、「/*」と等価のようです。トップページはアクセス制限したいけど、その他のURIにアクセス制限したくないURIが含まれているなんて要求には、対応できないようです。下記の例では、最後の「/bbbb」だけはアクセス制限したくないのに、「<url-pattern>/</url-pattern」のせいでアクセス制限されてしまいます。
/index.html ........ 管理者用トップページのHTML、アクセス制限したい。
/aaaa ................... ajax用のAPIであるURI#1、アクセス制限したい。
/bbbb .................. ajax用のAPIであるURI#2、アクセス制限したくない。
上記問題の対応ですが、1つは清く、単純に「<url-pattern>/</url-pattern」の記載を削除して省略したURIのアクセス制限をあきらめることです。
また、きれいではないですがリダイレクトを利用して回避する手もあります。welcome-file-list要素に記載したURIはアクセス制限なしとし、そこにはリダイレクトだけ書いたHTMLを置いておきます。リダイレクト先のページをアクセス制限します。
下記がその例です。まずは web.xml 。
<welcome-file-list>
<welcome-file>index.html</welcome-file>
</welcome-file-list>
<security-constraint>
<web-resource-collection>
<web-resource-name>admin</web-resource-name>
<url-pattern>/admin.html</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>admin</role-name>
</auth-constraint>
</security-constraint>
<security-constraint>
<web-resource-collection>
<web-resource-name>ajax</web-resource-name>
<url-pattern>/aaaa</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>admin</role-name>
</auth-constraint>
</security-constraint>
つづいて /index.html です。
<html>
<head>
<meta http-equiv="refresh" content="1;url=/admin.html">
</head>
</html>
/admin.html がアクセス制限したいURIです。この例では管理者用ページを想定して、この名称にしました。/admin.html の記載例は載せませんが、適当にやってください。
URIの構成は下記のようになります。
/index.html ........ admin.htmlへのリダイレクトのみ、アクセス制限なし。
/admin.html ....... 管理者用トップページのHTML、アクセス制限あり。
/aaaa ................... ajax用のAPIであるURI#1、アクセス制限あり。
/bbbb .................. ajax用のAPIであるURI#2、アクセス制限なし。
リソースファイルの読み込み.2016/10/27
動機.
GAEではファイルアクセスは限定的にしか提供されません。読み込みはできるが、書き出しの機能は無しと説明されています。
ソースファイルに直接埋め込むには大きすぎるデータやテキストでないデータなどの固定のデータをリソースファイルとしてjarに用意しておいて、それを読みだして使うのはよくある手段です。このリソースとしてファイルを利用する手段では、ファイル読み込みの機能が必要です。jar内に用意したファイルの内容くらいは読み込めるかなと探してみましたが、意外と見つからない。
自分で調べたところ、ある程度できるようになりました。ちなみに自分は、PNGで用意した画像から任意のものを選んで複数連結し、新しい1つの画像として返す使い方をしています。
似たようなケースとして以下のケースがありますが、いずれも本章で取り扱うのとは異なります。
- Google Cloud Storage上のオブジェクトのアクセス。
- DatastoreのBlobとして保存したオブジェクトのアクセス。
- appengine-web.xmlのstatic-files要素に記述しておいて、urlfetchでアクセス (アプリ外でもURLさえ分かればアクセス可能)。
リソースファイルの配置.
まずは準備としてファイルを用意し、プロジェクトのwar以下に置きます。ただしリソースファイルのURIがバレると、URI直アクセスでリソースファイルを取得できてしまいます。リソースファイルそのものは外部公開したくない場合、war/WEB-INF以下に置きます。war以下の場合もwar/WEB-INFの場合もどちらも、その下に任意のディレクトリを作って配置しても構いません。
下記は (プロジェクトトップディレクトリ)/war/WEB-INF/img 以下に置く例です。公式ドキュメントでは「appengine-web.xml Reference」に書かれています。resource-files要素でリソースファイルの定義であることを示し、その子要素としてinclude/exclude要素でリソースファイルのパスを指定します。パスの起点は
"(プロジェクトトップディレクトリ)/war" である点に注意してください。
<appengine-web-app>
...
<resource-files>
<include path="/WEB-INF/img/*"/>
</resource-files>
...
</appengine-web-app>
試しに上記の resource-files要素の記述をばっさりとなくしてみたところ、問題なく動いてしまいました。しかしドキュメントに記載されているのですから、 resource-files要素を記述するのが正しい方法と思われます。将来の実装変更により、記述しないと動かなくなる可能性もあります。
読み込み方法.
以下はリソースファイル読み込みのJavaのサンプルソースです。
String filename = "/WEB-INF/img/sample.png"; // リソースファイルのパス
URL fileurl = getServletContext().getResource(filename); // ServletContext.getResourceでURLを取得
File file = new File(fileurl.toURI()); // FileにはURIから作るコンストラクタだけ。URLからは作れない
InputStream instrm = new FileInputStream(file);
long size = file.length();
byte[] bytes = new byte[(int)size]; // このバッファをピッタリにしたかったのでFileを使ってる
int readsize = instrm.read(bytes);
ServletContext.getResourceメソッドでURLを取得すると、アクセスできました。ファイルアクセスしたいのにいったんURLとして取得しないといけないのがちょっとキモチワルイのですが、ServletContextクラスにはURLで取得するメソッドしかないので。
ServletContext.getResourceAsStreamでもできると思いますが、InputStreamから終端までの長さをあらかじめ得る手段がないので、上記のサンプルでは使用していません。
東京リージョンの使い方.2016/11/21
動機.
Googleからのメールで東京リージョンがサービス開始したというので、さっそく使い方を調べてみました。
本サイトのアクセスカウンタは、サイト開設以来ずっとKENT WEBで配布されていたものを利用させていただいていましたが、前回更新から自前のGAEアプリに変更しています。この時はまだ東京リージョンはサービスを始めていなかったので、us-centralリージョンを利用していました。東京リージョンを利用することで、このアクセスカウンタへのアクセスのレイテンシが軽減されることを期待しました。
制限事項.
まず最初に、リージョンを指定できるのはプロジェクト生成時のみです(公式ドキュメント)。プロジェクト作成後にリージョン/ゾーンを変更する手段は用意されていないようです。なので、本章の記載内容は「使い方」というより、「東京リージョンでGAEプロジェクトを始める手順」の説明です。
手順.
(2017/02/06追記)
2017/01中にGCPコンソールのUIが更新され、手順が変わっていました。現在の手順は以下のとおりです。
- まずは新規プロジェクトを作成します。GCPのコンソール左上の「ツールとサービス」メニューから「IAMと管理」
- 「IAMと管理」ページ面左端のメニューから「すべてのプロジェクト」
- 中央ペイン上の「プロジェクトを作成」ボタン
- 「新しいプロジェクト」ダイアログの「プロジェクト名」に作成したいプロジェクトの名称を入力
- ダイアログ右下の「作成」ボタンが有効になっているはずなので、ぽちっと
- ページ右上の通知の表示が変わるのを待つ
- 左上の「ツールとサービス」メニューから「App Engine」
- 「App Engineへようこそ」画面に変わるので、「初めてのアプリへようこそ」下の「言語を選択」からNode.js/Ruby以外の言語を選ぶ
- 「Your fitst app with (選択した言語)」画面に変わるので、地図もしくはリストから「asia-northeast1」を選択して「Next」
- 「準備しています…」画面に変わるので、しばらく待つ
- 「さっそく始めましょう。→」画面に変わるので、「次へ」もしくは下部の「チュートリアルをキャンセル」
すでにAppEngineプロジェクトを持っていても、手順8では「初めてのアプリ」と表示されます。気にしないでください。
また手順8でNode.js/Rubyを選択すると、手順9でリージョンを選択できなくなって行き詰ります。Standard Environmentは現在対応していない言語なので、手順8で選択肢が表示されることがヘンですが。
下記は2016/11/21の本記事公開時の内容です。
下記のとおりです。
- まずはGAEの新規プロジェクトを作成します。GCPのコンソール左上の「ツールとサービス」メニューから「IAMと管理」
- 「IAMと管理」ページ面左端のメニューから「すべてのプロジェクト」
- 中央ペイン上の「プロジェクトを作成」ボタン
- 「プロジェクト名」に作成したいプロジェクトの名称を入力
- 「新しいプロジェクト」ダイアログの「詳細設定を表示」をクリック
- ダイアログに「App Engineの地域」を選択するドロップダウンリストが追加されるので、「asia-northeast1」を選択
- ダイアログ右下の「作成」ボタンが有効になっているはずなので、ぽちっと
- ページ右上の通知の表示が変わるのを待つ
- 手順4で入力したプロジェクト名で、GAEアプリをデプロイ
プロジェクトの作成場所だけでなくプロジェクト名も、プロジェクト生成時にしか決められない点に注意してください。ダサいプロジェクト名で作ってしまって変更したいとなると、後々面倒です。
データについて.
すでに稼働中のプロジェクトの場所を移動したい場合、プロジェクトを作り直すしかありません。プロジェクト名はGCP内でユニークなので、既に存在するプロジェクトとは別の名称で作り直す必要があります。
ここで、Datastore/GCSに保存したデータはプロジェクト単位で独立しています。アプリのコードはデプロイしなおせば終わりですが、データは別途移動させる必要があります。古いプロジェクトのデータストアを使い続ける設定も可能でしょうが、新旧のプロジェクトでリージョンが異なるので、物理的に遠距離へのネットワークアクセスがGoogleのサーバ側で発生し、データアクセスが非常に遅くてリージョン移行する意味がなくなってしまいます。
具体的なデータ移行の手順は、「プロジェクト間でのデータ移行」で説明しています。
プロジェクトの場所について.
領域とかゾーンとか、何?
公式ドキュメントのこことか読んでいると、場所を表現する単語がいろいろ出てきて混乱しそうです。公式ドキュメントでもページによって英語の原文でのある単語が、日本語ページではカタカナになっただけだったり、対応する日本語に置き換えられていたりと統一されていないので、「この単語とこの単語は同じ意味みたいだけど、本当か?」と疑いながら読む羽目になってしまうせいです。
ようは場所に関して3段階のサービスレベルが存在します。
- ゾーン(Zone) : 要するのデータセンターのある場所と思います。
- 地域 = リージョン(Region) : 地理的に近くにあるデータセンターをまとめて扱うための単位。
- 複数地域 = マルチリージョン : 自動スケールに利用可能な範囲のリージョンをまとめたもの。
東京リージョンとすでにサービス中の台湾リージョンは、他のリージョンと比べると地理的には比較的近くですが、リージョンの単位で別物です。提供されるサービスも違いますね。
信頼性.
公式ドキュメントに「ゾーンは、地域内の単一の障害ドメインとみなすことができます」との記載があります。サービス停止などの影響のある障害が起きると、このゾーン単位で影響があるものと思います。一方でリージョンでは冗長性があり、障害に強いはず。
GAEではリージョン単位でしか場所を指定できないので、あまり考えなくていいかもしれません。
/robots.txtでの404エラー回避.2016/12/01
robots.txtについて.
ネットで「robots.txt」を検索すればすぐわかりますが、検索エンジンがネット上に存在する数多のサイトの情報を集めるためのロボット(一般的にはこれをクローラーと呼びます)に、サイト内の情報収集許可を与えるためのファイルです。
たぶんGCEとか他のGCPも含めてそうだと思うのですが、GAEアプリはサーブレットで動的にHTMLを生成したり、ajaxで非同期に返したデータをもとにスクリプトで動的にHTMLを生成したりと、静的にHTML運用することがほとんどないと思います。また登録アカウントしかアクセスできないサービスを提供しているケースもあります。これら検索エンジンに登録されたくない、登録されても意味がない、言い換えれば、検索エンジンで検索しても見つからないようにしたいのが、webアプリだと思います。
単に、GAEコンソールのダッシュボードページのクライアントエラーの項目に「/robots.txt」が毎日何件か出てきてうざくて消したいなー となったりします。
これらを実現するには、GAEアプリにも/robots.txtを設置します。
GAEアプリでのrobots.txt設置.
robots.txtの書き方は、いろいろなサイトで説明されていると思うので、ここでは割愛します。本サイトはGAEアプリへの設置方法のみ説明します。
手順は以下のとおり。
- まずはrobots.txtを、下記のパスで作成します。
(プロジェクトトップディレクトリ)/war/robots.txt
- (プロジェクトトップディレクトリ)/war/WEB-INF/appengine-web.xml のstatic-files要素にrobots.txtの項目を追加します。以下のようになります。
<appengine-web-app> ... <static-files> ... <include path="/robots.txt"/> </static-files> ... </appengine-web-app> - アプリをデプロイする。
単に/robots.txtを置いただけだと、クローラーからはアクセス不可能なので、404エラーが出続けます。/robots.txtへのアクセスを可能にするには上記手順2.が必要です。
Memcache利用上の注意.2017/01/12
Memcacheが速くない?
Memcacheは主にDatastoreへのアクセスを高速化する目的で使うものと思っていました。で、そのつもりでコードを書いて、実際にどれくらい違うんだろうとMemcacheへのアクセスやついでにDatastoreへのアクセスしている個所に処理時間を計測するコードを突っ込んでみると、なんか、速くない気がする。
測ってみた.
ちゃんとデータ取ったわけではなくて、ログに吐いたMemcacheやらDatastoreやらへの処理時間を拾い読みしてみただけなのですが、速いときは速いけど、異常に遅いときがあります。Memcacheに保存したオブジェクトは、1kB以下のPNGと、5個程度のプロパティを持つDatastoreのエンティティと、サイズは小さめのものばかりです。対象のAPIはMemcacheService.get/putです。
何度もアクセスを繰り返していると大体の傾向がつかめてきました。どうも3パターンあるようです。
| パターン | 処理時間 | 発生条件 | 原因についての考察 |
| A | 2000ms程度以上 | GAEインスタンス起動直後だけらしい。 | Javaクラスのローディング・初期化のために時間がかかっているのでは。 |
| B | 100〜400ms程度 | 他のMemecacheアクセスとアクセスタイミングが重なったとき。 | Memcache自身の排他制御、RPCの都合もしくは、タスクスイッチによる遅延? |
| C | 10ms以下 | 上記以外のケース。 | これが本来のMemcacheの性能と思われます。 |
リージョンはus-central/asia-northeast1で試してみましたが、結果はほぼ同じでした。日次や時間帯を変えてみても、ほとんど結果に変化はありません。
パターンA.
GAEインスタンスを起動したリクエストの最初のMemcacheアクセスでのみ、このパターンになります。おおむね3000〜4000ms程度かかりますが、ベストケースでは2000ms程度のこともありました。同じリクエスト内での2回目以降のMemcacheアクセスはこれほど遅くないこと、GAEインスタンスの起動を伴わないリクエストの最初のMemcacheアクセスもこんなに遅くないことから、MemcacheServiceクラスのローディングとクラスの初期化に時間がかかっていると推測されます。
パターンB.
パターンAに当てはまらないケースで、突発的に少し遅くなることがあります。複数のリクエストのログを眺めていて、他のリクエストのいずれかのMemcacheアクセスとピッタリアクセスのタイミングが一致した場合にこのようになることに気づきました。
GAEのサーバは、GAEに実装された機能ごとに複数の小さなサーバに分割して実装され、そのサーバをRPCで利用しています。(公式ドキュメントで少し前に読んだ記憶があります。今回この記事を書くにあたって探しなおしてみたのですが、見つかりませんでした。)
Memcacheもその「小さなサーバ」の1つであり、Memcacheに保持するオブジェクトの排他制御などの都合で、そのサーバに同時にリクエストがあれば一方が待たされる実装のようです。
またRPCであるので、次に実行権が回ってくるまで待たされます。RPCに伴うタスクスイッチが遅いという話も聞いたこともあります。
パターンC.
上記パターンA/Bに当てはまらなければ、本来のMemcacheの性能が発揮されます。大体は3ms程度です。
しかし、今回Memcacheに保存したオブジェクトについては、もとはDatastoreのエンティティもしくは、Javaパッケージ内のリソースです。Datastoreに保存したエンティティに直接アクセスしても5msくらい、Javaパッケージ内のリソースの読み出しも1kB以下なら3ms以内には終わっているので、あまり速度面での恩恵が感じられません。
今回ちゃんとした計測をしなかったのは、パターンBの発生確率はアプリの造りに影響を受けると予想したからです。タイミング依存なので、自分の作ったアプリで採ったデータで結論を出しても、そのまま違うアプリには当てはまりそうにないと思ったので、簡単に確認できる範囲にしました。
対策.
キャッシュなんだから速いだろうと盲目的に信じていたら、処理速度的にはそうでもないようです。上記パターンA/Bのような一時的な性能の低下はMemcache以外の機能でも発生してるのを見たことがあります。具体的にはDatastoreとか、AppIdentityServiceです。パターンAは性能の低下が大きいですが、発生条件が限られていますし、Javaを使う以上回避できないでしょう。対策すべきはパターンBのみとなりますが、下記の回避策が有効と思われます。
Memcache APIのコール回数が多ければ多いほど、パターンBの発生リスクが多くなるので、単純にMemcache APIのコール回数を減らすことが有効です。Memcache.put/get/delete
APIは1オブジェクト単位でしかアクセスできないのでオブジェクト数分のアクセスが必要ですが、Memcache.putAll/getAll/deleteAll
APIなら複数オブジェクトをまとめて1回のAPIコールで処理できます。コードが複雑で読みづらくなることがありますが、できるだけMemcache.putAll/getAll/deleteAllを使用するよう心掛けないと、Memcacheの利用が処理速度の向上には結びつきません。
また「キャッシュなんだから速くなる」という妄信を捨てるべきかもしれません。Datastoreエンティティの読み書きには料金が発生しますが、Memcacheの場合は読み書きだけでは料金は発生しません。これは無料の共有(Shared)Memcacheでも有料の専有(Dedicated)Memcacheでも同じです。Memcacheは「Datastoreアクセスを減らして課金額を下げる」ことを主目的に使うべきなのかもしれません。
対策というか、心得みたいになってしまいました。
サービスの利用.2017/03/03
動機.
作りかけのアプリでタスクキューを使おうとして、色々と嵌ってしまいました。その途中でサービスにも手を出してみて、ここでも嵌ってしまいました。解決はしましたが、もう嵌らないように忘備録を残します。
サービスって何.
公式ドキュメントの説明は、日本語訳でもちょっとわかりにくいと思いますが、「1つのアプリを複数の実行ファイルで構成するための仕組み」と考えれば、理解しやすいと思います。
旧来「モジュール」と呼ばれていた機能が、最近になって「サービス」へと名称変更されています。公式ドキュメント内をうろついていると、「サービス」と表現されている個所もあれば「マイクロサービス」と表現されている個所もあったり、旧称の「モジュール」のままの箇所もたまにあったりと、散らかってて混乱しそうです。
サービスっていつ使うの.
代表的なユースケースは、アプリに実装したい複数の機能で、最適なオートスケールの設定が機能ごとに異なるケースになると思います。appengine-web.xmlによるオートスケールの設定などはサービス毎に独立して設定可能なので、サービスを利用すればこのようなケースを実現できます。
また一時的に特定の機能へのリクエストが集中して発生するような造りのアプリの場合、リクエストが集中発生している最中はインスタンスの空きが少なくなりがちなので、UA(ユーザ・エージェント)からのリクエストでもスピンアップが発生し、結果的にユーザがレスポンスが遅くなったと感じてしまうケースがあります。GAE/Jだとスピンアップが遅いという問題に簡単に出くわしてしまう状況が作られているわけです。
このようなアプリではUIから直接のリクエストを処理するサービスと、リクエストが集中する特定の機能を別のサービスとして分けることで、ユーザへの影響を減らせます。
設定.
appengine-web.xmlでmodule要素でサービス名を定義し、GAEにデプロイするだけで、新しいサービスが出来上がります。module要素はオプション扱いですが、定義がなければ「default」という名称のサービスと解釈されます。
実際はこれだけでは、いくつか嵌りどころがありますので、回避方法を述べます。
dispatch.xmlがあったほうがいいかも.
各サービスのweb.xmlのservlet-mapping要素で、URIに対するリクエストハンドラの定義が被らないよう定義にし、なおかつ、各web.xmlは自サービスで実装したリクエストハンドラだけを定義しているのであれば、dispatch.xmlは必要ありません。
しかし全サービスでweb.xmlは共通にするとか手を抜こうとすると、アプリで用意したリクエストのハンドラがどのサービスに存在しているかを示す手段が、dispatch.xmlにしかないようです。
きっちりサービスごとにweb.xmlを定義するか、dispatch.xmlを用意するかの2択です。
dispatch.xmlのデプロイ.
dispatch.xmlは下記のパスに置きます。
(プロジェクトトップディレクトリ)/war/WEB-INF/dispatch.xml
しかしEclipseプラグインからアプリをデプロイの操作を行っても、dispatch.xmlは一緒にデプロイしてもらえません。デプロイ時のEclipseのコンソールには下記のログが出ます。
Skipping dispatch.xml - consider running "appcfg.sh update_dispatch <war-dir>" or using the "--auto_update_dispatch" option
このログにあるように、GAE SDKのコマンドラインツールであるappcfgを使って、dispatch.xmlだけを個別にデプロイするしかないようです。appcfg.cmdにパスが通っていれば、下記のコマンドで出来ます。
appcfg update_dispatch (プロジェクトトップディレクトリ)/war
dispatch.xmlのurl要素の記述.
タイトルどおり、dispatch.xmlのurl要素のコンテンツに記述するリクエストハンドラのURIの記述の仕方によっては、デプロイがエラー終了します。
例えば、「/handler_hoge」というURIだけサービス「hoge」にルーティングしたい場合、下記のように記述すればOk。パス部分だけを指定したい場合でも、ホスト名部分(下記の例では「*」)の記述がないとエラーになるようです。web.xmlのservlet-mapping要素下のurl-pattern要素とかとは記述方法が異なるようです。
<dispatch-entries>
<dispatch>
<url>*/handler_hoge</url>
<module>hoge</module>
</dispatch>
</dispatch-entries>
デプロイしたdispatch.xmlの取り下げ.
一度デプロイしたdispatch.xmlを取り下げる方法が見つかりません。そのようなコマンドはappcfgのヘルプにも記載がありませんし、dispatch.xmlを削除して「appcfg
update_dispatch ...」してみても、動作は変わりませんでした。
dispatch.xmlから有効なdispatch要素を削除(またはコメントアウト)して、デプロイしなおす(もちろんappcfgで)ことで、dispatch.xmlの以前の記述内容を取り消すことが出来ました。こんな方法でいいのかどうかは不明ですが。
ソースの構成.
ビルドのターゲットがサービスごととなり、複数になってしまうので、war配下を含めてEclipseのプロジェクト/ディレクトリ構成に悩むことになります。
考えられる選択肢とそれぞれのメリット/デメリットを考えてみました。
| No. | 構成方法 | メリット | デメリット |
| 1 | サービスごとにEclipseのプロジェクトに分割する。 |
|
|
| 2 | プロジェクトとプログラム部分のソースは全サービス共通で1つで、サービスごとにwarディレクトリ以下を用意し、これらを切り替えながらデプロイする。 |
|
|
| 3 | プロジェクトは全サービス共通で1つで、サービスごとにapplication-web.xml/web.xmlを用意し、これらxmlを切り替えながらデプロイする。 |
|
↑に加えて、
|
| 4 | プロジェクトは全サービス共通で1つで、サービスごとにapplication-web.xmlのみ用意し、これを切り替えながらデプロイする。 |
|
↑に加えて、
|
タスクキュー(pushキュー)の利用.2017/03/03
(2020/08/06追記)
「タスクキューの概要」の注意書きに記載のとおり、タスクキューはすでにDeprecatedステータスになっています。代わりにCloud Tasksが使用できます。
動機.
前章でちょっと述べたとおりですが、作りかけのアプリでタスクキューを使おうとして、色々と嵌ってしまいました。本章も「転ばぬ先のなんちゃら」です。
pushキュー
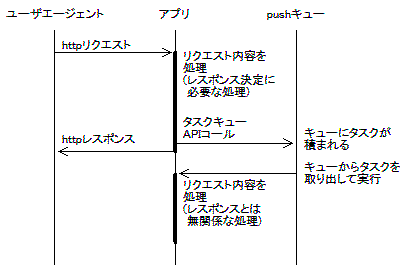 公式ドキュメントでの説明は分かりにくいかもしれませんが、時間のかかる処理の一部を、後回しにして実行するための仕組みです。
公式ドキュメントでの説明は分かりにくいかもしれませんが、時間のかかる処理の一部を、後回しにして実行するための仕組みです。
GAEのフロントエンドには通称「60秒ルール」と呼ばれる制限があります。デフォルト設定では、リクエストの内部処理は60秒以内に済まさないと、強制終了させられるというものです。また60秒以内であっても、ユーザに返すレスポンスは、遅いより速いほうがいいに決まっています。
ユーザからのリクエストをトリガとして始めた処理のうち、httpレスポンスを決定するには必要ない処理は別のハンドラに実装しておき、httpレスポンスを返す前にそのハンドラのURIをpushキューに積むことで、GAEがリクエストの処理終了後にこのハンドラを呼んでくれます。
図にすると右のような感じ。
起動したタスクは、デフォルトのオートスケーリングに設定されたサービスでも、最大10分まで動作を続けることができるのも特徴です。
またユーザにレスポンスを返すことができない半面、タスクのリクエストハンドラがエラーステータスで終了すると、一定の条件でリトライを行ってくれる便利な面もあります。
設定.
特に設定をしなくても、「default」という名称のpushキューがアプリには存在しています。キューの性能を指定したり、複数のキューにタスクを振り分けたりしたい場合は、下記のパスにqueue.xmlを作って定義し、デプロイします。
(プロジェクトトップディレクトリ)/war/WEB-INF/queue.xml
下記がqueue.xmlの記述例です。タスクを起動するレートは高めの50/sに、リトライしてもエラー回避し難いケースを想定してリトライを少なくしてあります。
<queue-entries>
<queue>
<name>queue-name</name> ←キュー名
<mode>push</mode> ←pushキュー
<target>target-service</target> ←リクエストハンドラの存在するサービス
<rate>50/s</rate> ←タスク起動のレート
<retry-parameters>
<task-retry-limit>1</task-retry-limit> ←エラー終了時のリトライ回数は1回
</retry-parameters>
</queue>
</queue-entries>
別サービスのハンドラを起動する
target要素を記述すると、起動対象となるサービス(公式ドキュメントでは旧称の「モジュール」と記述されています)を指定することもできます。複数のサービスを作成していて、web.xmlにすべてのリクエストハンドラをまとめて記述してあり、dispatch.xmlを記述しなくても(前章の表No.4のケース)、target要素を記述すれば指定のサービスにリクエストが送信されます。
上記の例では「target-service」という名称のサービスのハンドラを起動します。
タスクの作成.
com.google.appengine.api.taskqueueパッケージにAPIがあります。TaskOptionsクラスでタスクのパラメータを指定したインスタンスを生成し、QueueFactory.getQueue/getDefaultQueueで取得したQueueにaddします。下記がそのサンプルです。
TaskOptions options = TaskOptions.Builder.withUrl("/servlet_uri") ←リクエストハンドラのurl
.method(TaskOptions.Method.GET) ←そのハンドラをたたくリクエストのメソッドを指定
.param("userId", userid)
.param("requestTime", Long.valueOf(new Date().getTime()).toString()) ←キューに積んだ時刻をパラメータにしてみた
;
Queue queue = QueueFactory.getQueue("queue-name"); ←タスクを積むキューを指定
queue.add(options);
メソッドに注意.
タスクのリクエストハンドラが叩かれる際のhttpリクエストのメソッドのデフォルトは、POSTです。Eclipseのテンプレートのソースに最初から用意されているdoGetメソッドにハンドラを実装してしまうとメソッドが合わないので、リクエストハンドラが叩かれる際に、405エラーが発生します。
上記のサンプルではGETメソッドを指定して回避しています。リクエストハンドラにdoPostメソッドを実装しても構いません。
Cloud Tasksの使い方.2020/08/06
「タスクキューの概要」の注意書きに記載のとおり、タスクキューはすでにDeprecatedステータスになっています。タスクキューはGAEに実装された機能なので、GAE以外からは使用できません。タスクキューのPushキューをGAEの外に出して、GAE以外からも使えるようにしたものがCloud
Tasksであると理解して良さそうです。Cloud TasksにはPullキューが無いことを除けば、実際APIを使ってみてもタスクキューのPushキューとほとんど同じ感覚で使えます。ただしAPIそのものは別物なので、コードは置き換えが必要になります。
タスクキューとCloud Tasksの違いは「タスクキューからCloud Tasksへの移行」で説明されているとおりです。
特に第2世代VMであるJava11には、タスクキューは提供されません。Cloud Tasksを使用することが必須になります。第1世代VMであるJava8でもCloud
Tasksは利用可能ですので、これから非同期処理を実装するのなら、Cloud Tasksを使用した方が良いでしょう。
Pullキューが必要な場合は、「Pub/SubのPullキューを使え」ということになっています。想像してみると、完全にPub/SubのPullキューと同じとしか思えません。
またタスクキューのREST APはすでに機能停止しており、「Cloud Tasks REST API」に記載のとおり、「Cloud TasksのREST APIを使え」ということになっています。
これも長くなってしまったので、別ページにまとめました。
Cloud Schedulerの使い方.2020/08/06
「Java8用cronを使用してタスクのスケジュールを設定する」の注意書きに記載のとおり、cron.xmlを使用してGAEのcronを設定する方法はDeprecatedステータスになっています。cron.yamlを使用すればまだGAEのcronを使えるようですが、この際だからいつか終了するであろうことが予想されるcronを諦めて、Cloud
Schedulerの使い方を調べてみました。
cronはGAEに実装された機能なので当然GAEでしか使えません。cronをGAEから外に出してGCPのサービスに位置付けたのがCloud
Schedulerと理解して良さそうです。
タスクキューと異なり、第2世代VMであるJava11でもcronは提供されています。しかし「cron構成ファイルについて」を読むと、Java11ではcron.xmlは登場しませんので、cron.xmlは使用できなくなっていると思われます。
Cloud SchedulerならJava8/Java11どちらでも同じように使用できます。これから定期実行する処理を実装するなら、Cloud
Schedulerを使用した方が良さそうです。
これもCloud Tasksくらいに長くなりそうなので、別ページにしました。
Copyright 2005-2024, yosshie.